Change log
Current version: 1.4
Version history
1.4
- Download scraped images from instagram profile
- Save url of an image to database instead of path of downloaded file
- Display Instagram account and scraped data in web application
- Improve commands to make them easier
python main.py fb-search <"Search Query"> <results> <option_1> <option_2> ...
Options:
--post # Search for posts based on given query
--results # Number of results
--people # Search for people based on given query
--group # Search for group based on given query
--place # Search for place based on given query
--event # Search for event based on given query
--page # Search for page based on given query
python main.py fb-account <facebook_id> <option_1> <option_2> ...
Options:
--work # Scrape work and education information from the given facebook account
--contact # Scrape contact data from the given facebook account
--location # Scrape location data from the given facebook account
--family # Scrape family members data from the given facebook account
--name # Scrape full name from the given facebook account
--friends # Scrape friends list from the given facebook account 🛑 Page not support
--images # Scrape images from the given facebook account
--recent # Scrape recent places from the given facebook account 🛑 Page not support
--reels # Scrape urls for reels from the given facebook account
--reviews # Scrape reviews from the given facebook account
--videos # Scrape urls for videos from the given facebook account
--da # Download all videos from the given facebook account
--dn # Download only new videos from the given facebook account
--posts # Scrape all posts from the given facebook account
--details # Scrape details of posts from the given facebook account
--likes # Scrape likes from the given facebook account
--groups # Scrape groups from the given facebook account
--events # Scrape events from the given facebook account
python main.py insta-account <id> <option_1> <option_2> ...
Options:
--images
--stats
1.3
- Change the name of a project to "Meta Spy"
- Scraping images from instagram profiles
- Save scraped images to the database and display on local server
- Delete AI features
python main.py instagram-profile-images <instagram_id>
1.2
- Real time result while scrolling in scrapers:
- Post url
- Images
- Friend list
- Automatically save scraped data to JSON file
- data available in this directory /facebookspy/scraped_data/
- Running scrapers parallely while using commands:
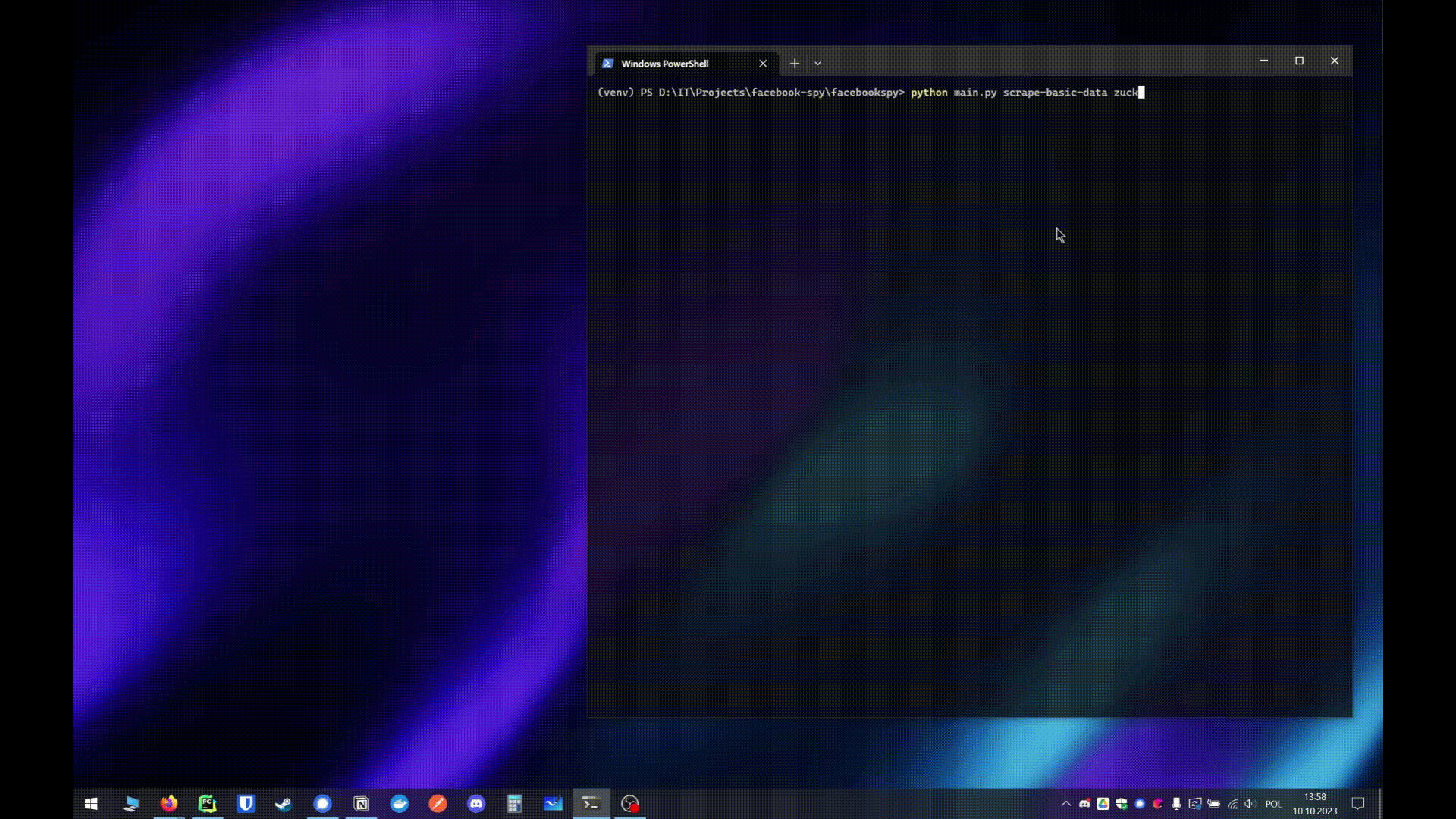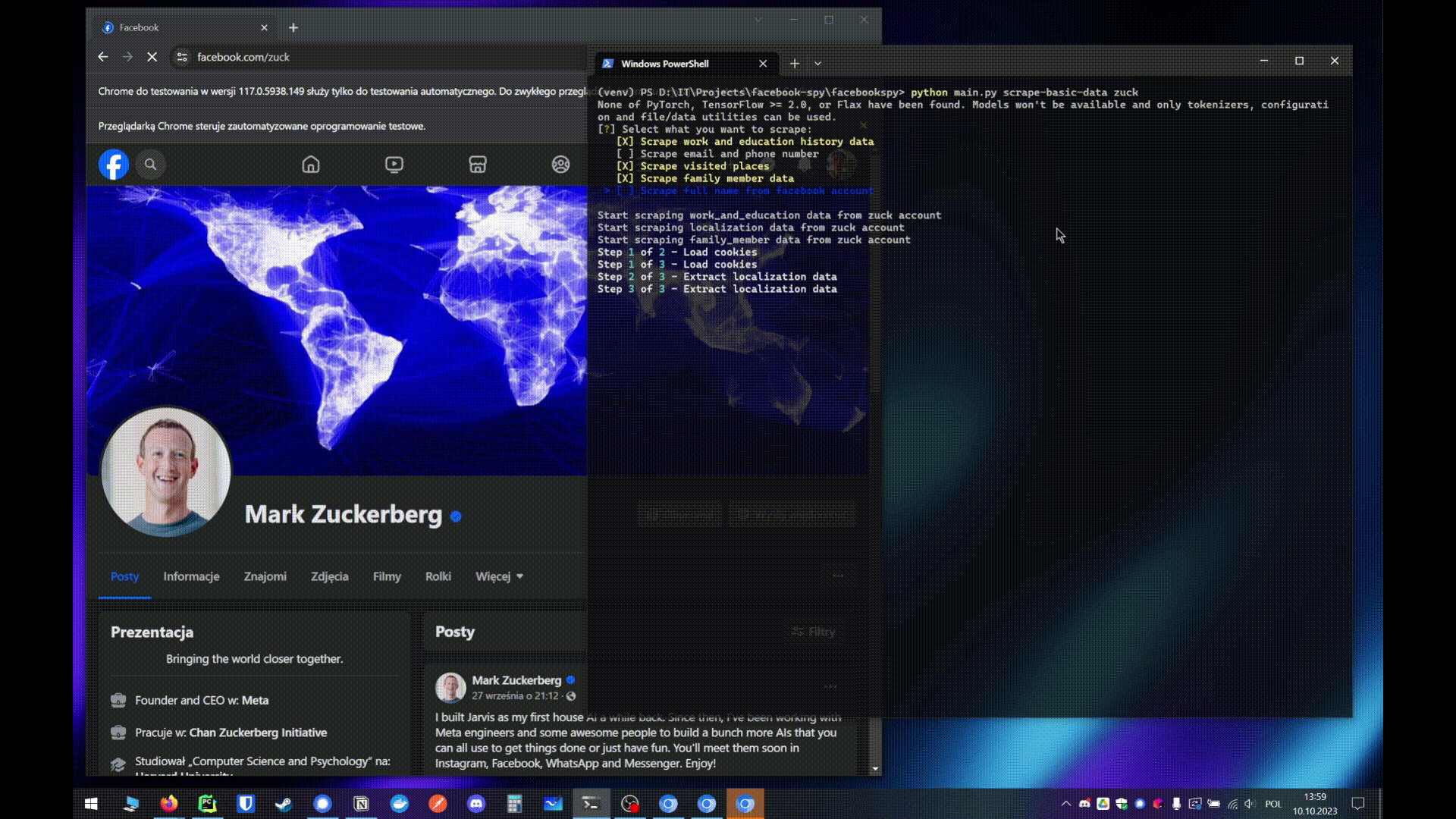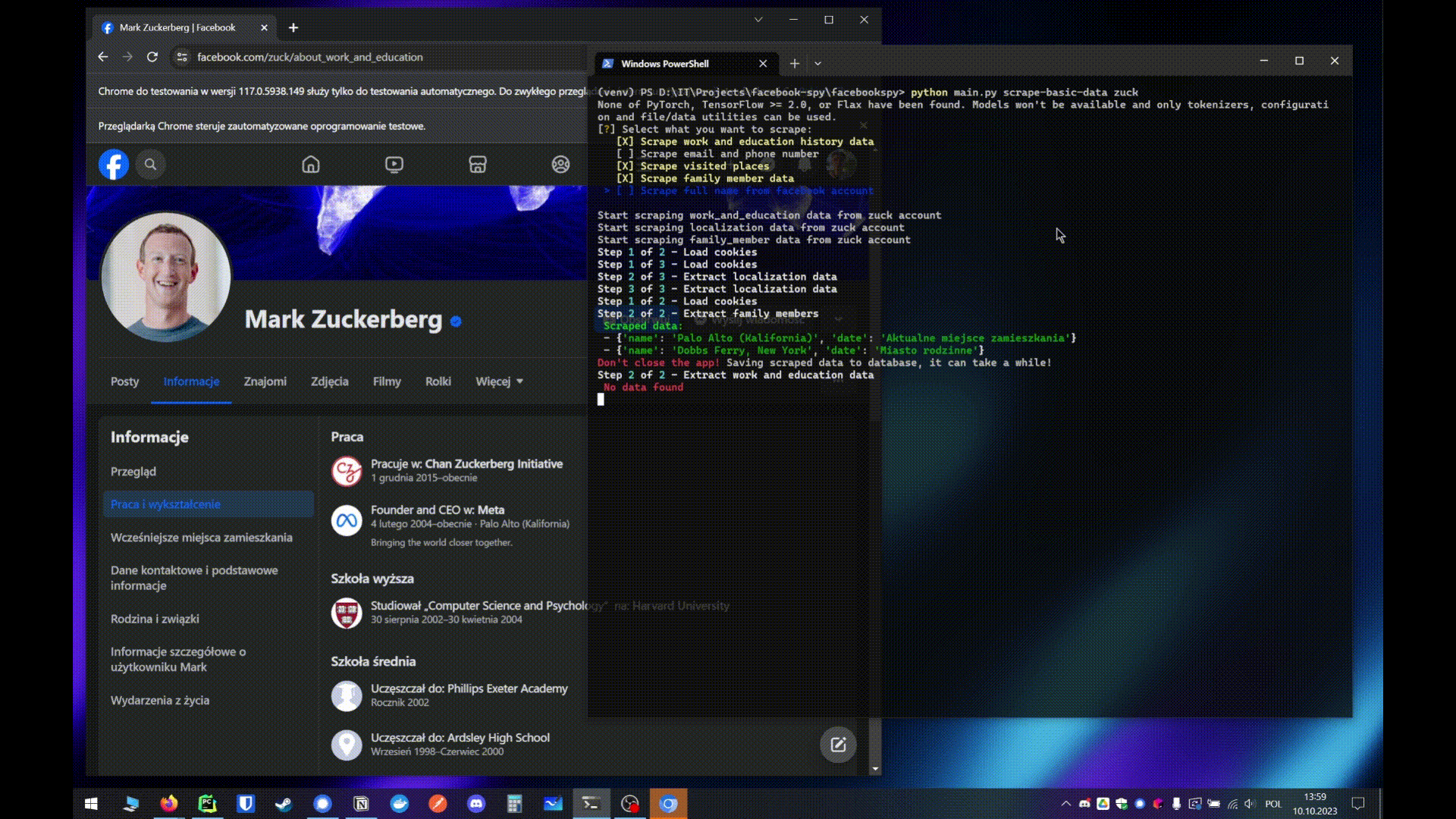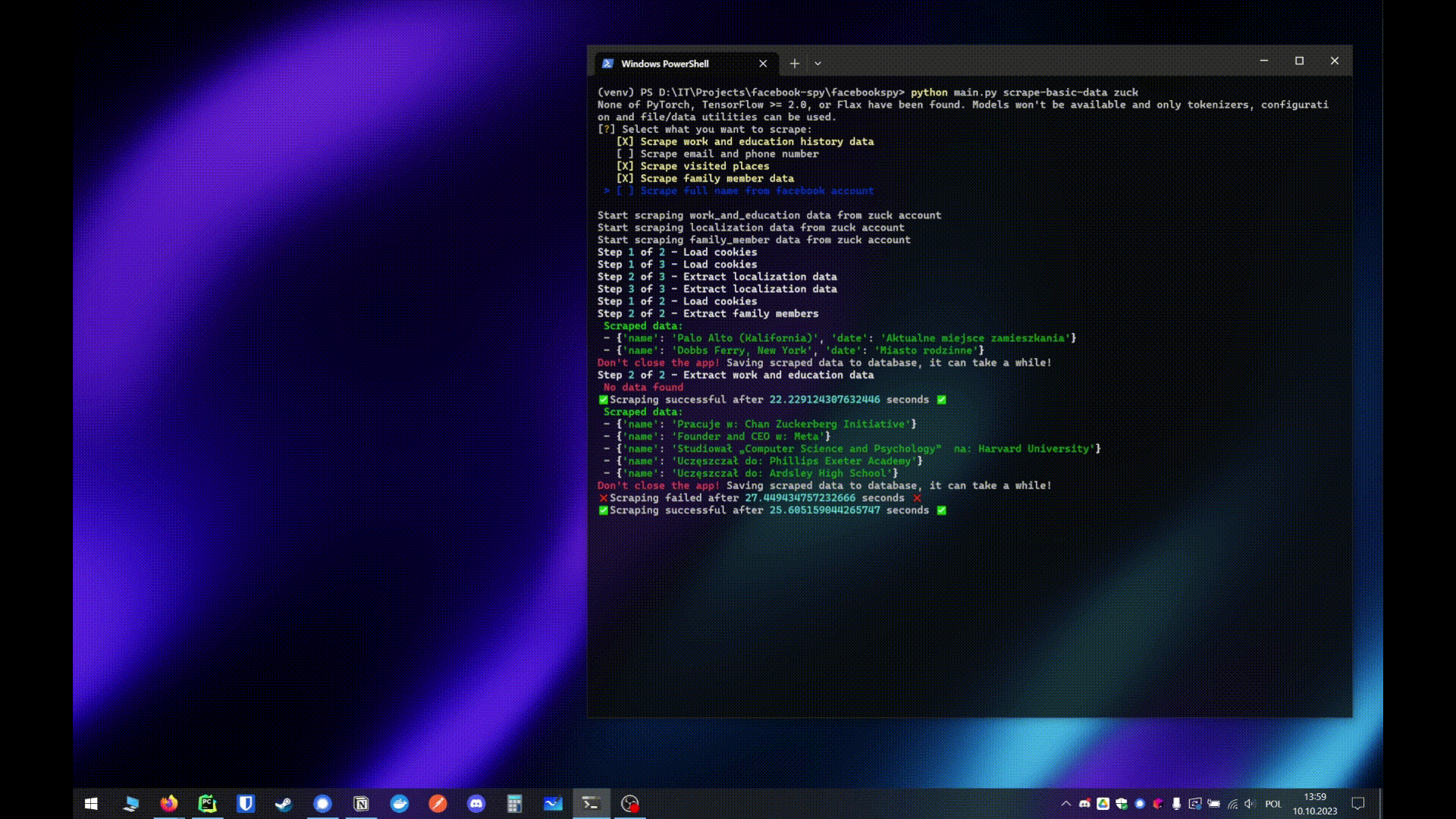
- python main.py python main.py scrape-basic-data
- Automatically run all selected scrapers at the same time
- python main.py full-scrape
- If 2 or more usernames are provided it's gonna scrape all users at the same time
- But if only 1 username is provided it's gonna run all selected scrapers at the same time
- python main.py python main.py scrape-basic-data
- NEW command - SEARCH
- This command allows to search for: places, pages, groups, person, events and posts
- This command also has a parallel feature
python main.py search < " Search Query Here " > < number_of_results >
1.1
- Improve local web application
- Delete React application
- Add templates for fastAPI
- Display all information about specified Person on a single page
- Delete docker and docker-compose files
- Fix scraping URLS of a posts from user's profile
- Improve scraping details of a post
- Number of likes
- Content (text)
- Image urls
- Author
- Post url
- Improve typehints
- Add new selector for scraping videos from user's profile
New commands:
python main.py scrape-person-post-details <facebook_id>
1.0
- Delete command to run web application without docker
- Post classification using transformers to check if post content is possitive or negative and save those data to database
python post-classifier <option>
Options:
--all-posts // Run post classification for all posts from the database
--id // Run post classification for specified post from the database
--person-id // Run post classification for a specified person from the database
- Add missing typehints
- Change the structure of a project
- Friend crawler (This command works similarly to the command that scrapes data about a given user's friends list. The difference, however, is that after scraping and creating Friend objects, it also creates objects for the CrawlerQueue model and after successfully scraping friends for one user, it proceeds to scraping the list of friends for the next user in the queue.)
Run crawler
Start crawler for specified facebook account
python main.py friend-crawler <facebook_id>
Display queue
Display all objects available in the queue
python main.py display-queue
Delete queue object
Delete specified queue object
python main.py delete-queue-object <id>
Clear queue
Delete all objects from the queue
python main.py clear-queue
- Option to scrape multiply users in full-scrape command
python main.py full-scrape <facebook_id> <facebook_id> <facebook_id>
0.9
- Add repository functions to return all data for specified Person object
- Implement LangChain and free Open Source LLM model to create summary for specified Person object based on scraped data
- Add command to create summary
- Add command to save all scraped data and summary to PDF file for specified Person object
- Fix saving events and groups if there is no data
- Disable displaying logs from Selenium in the console
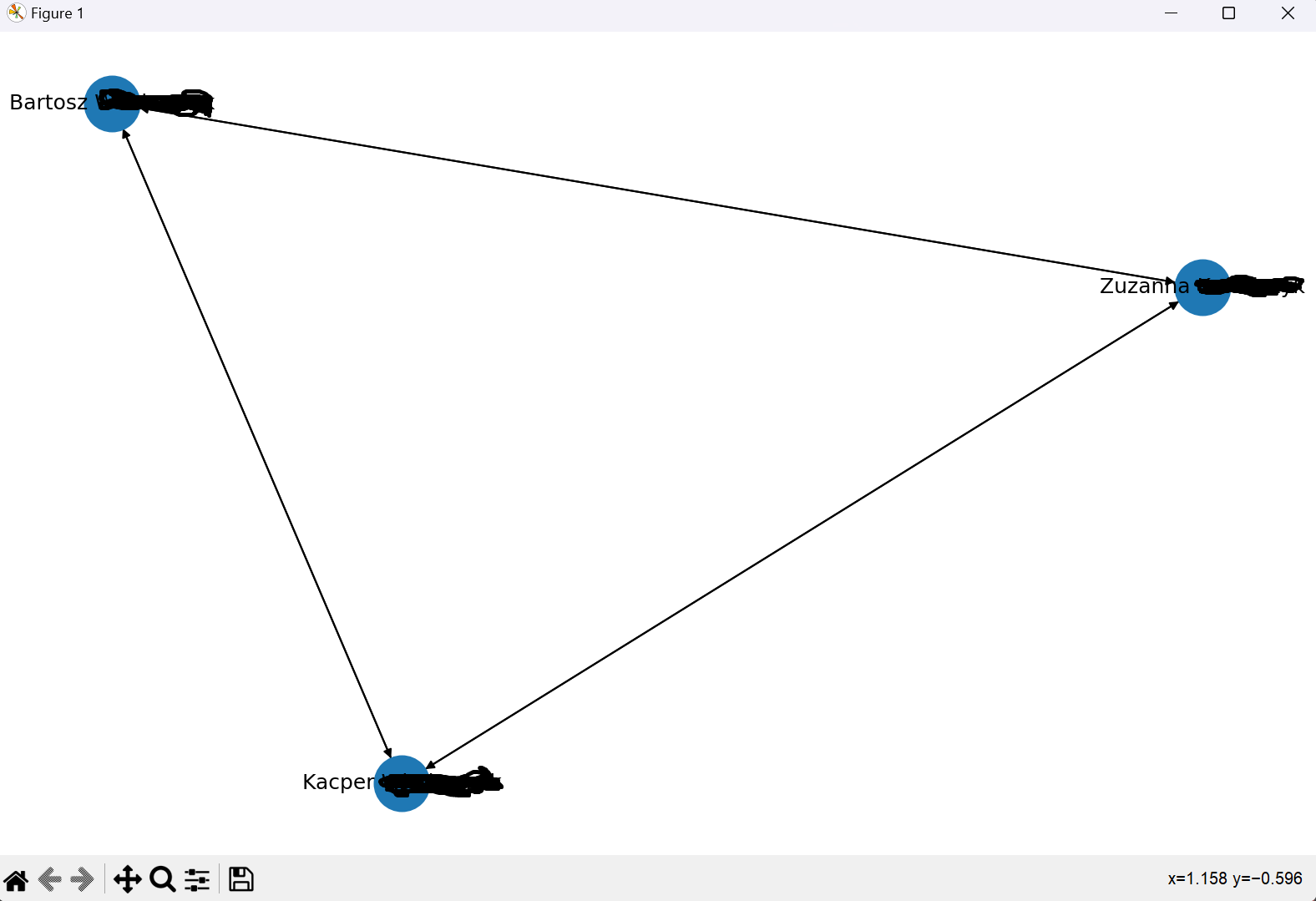
- Add command to create graph of the connections between Person objects based on their friends
New commands
To create a graph of connections between Person objects based on their Friends use this command
python main.py graph
Save scraped data for specified Person object to PDF file
python main.py report <facebook_id>
Use free open source LLM model to create a short summary for specified Person object based on scraped data
python main.py summary <facebook_id>
V0.8
- Scrape user's groups
- Scrape user's likes
- Scrape user's Events
- Optimalized scrolling
- Add number_of_friend field in Person model
- Pytest for all FastAPI endpoints and models
- Add email and phone_number field to Person model
- Fix saving full_name field to Person model
- Add scraper for Contact data
- Refactor scrapers to make them simpler
- Create a few commands (more details in commands page) with a drop down list to select which scrapers use
V0.7
- Scrape facebook posts urls from a facebook account
- Scrape post details (number of likes;comments;shares, content etc.)
- Add information about saving data to database
- FastAPI endpoint to return a list of posts for a give Person object
- React page to display a list of posts for a given Person object
- Refactor commands
- Display time that was taken to finish pipeline
- Update 'server' command to run FastAPI + React app with or without Docker
python main.py server --d
python main.py server
- Add shell script to run React application with Python
- Add Docs website which you are using now